https://wondangcom.tistory.com/2769
머신러닝 목차
머신러닝 1. 머신러닝 소개 1.1 인공지능이란 (혼공머신) - 4차산업 혁명 시대에 꼭 필요한 인공지능에 대해 알아 보자. 링크 : https://wondangcom.tistory.com/2771(2024.3.7) 1.2 머신러닝을 사용하는 이유 (핸
wondangcom.tistory.com
목표
- 실제 데이터를 살펴 본다.
- 실제 데이터에서 우리가 필요한 데이터를 추출해 낸다.
- nan 값을 처리하는 방법들을 이해한다.
- 최근접 이웃에서 과적합 되었을 때 하이퍼파라미터를 이용하여 과적합 방지를 하는 부분을 살펴 본다.
데이터 출처
https://www.kaggle.com/datasets/blastchar/telco-customer-churn?resource=download
Telco Customer Churn
Focused customer retention programs
www.kaggle.com
1. 최근접 이웃 분류 (K-NN) 알고리즘

최근접 이웃 분류 알고리즘은 위의 그림 하나로 모든 원리가 설명이 된다.
녹색 점의 위치를 무엇으로 분류해야 하는지 확인을 할때 k의 값을 3으로 설정 했을 때 실선의 영역으로 자신에게 가장 가까운 표본을 3개 선택 한다. 거기서는 빨간세모가 더 많기 때문에 세모로 인식한다.
그 다음 실선 영역은 k=5 일때 자신에게 가장 가까운 표본을 5개 선택한다. 그 때는 녹색은 파랑사각형으로 인식하게 된다.
이와 같이 자신의 위치로 부터 유클리드 거리가 가장 짧은 순으로 k개를 선택해서 그 중 표본의 갯수가 많은 것을 자신으로 판단 한다는 것이 최근접 이웃 분류 알고리즘이다.
최근접 이웃 회귀 알고리즘은 선택은 위와 동일하게 하지만 거기서는 평균값을 취하는 것이 최근접 이웃 회귀 알고리즘이다.
2. 데이터셋 분석
위의 데이터를 다운로드 받으면 속성은 다음과 같다.
customerID : 소비자의 식별자
gender : 성별
SeniorCitizen : 노인인지의 여부
Partner : 배우자의 유무
Dependents : 자녀의 유무
tenure : 고객의 가입 기간 (개월 수)
PhoneService : 휴대폰 서비스를 가입 했는지의 여부
MultipleLines : 여러 개의 통신선을 서비스 받고 있는지의 여부 (Yes, No, No phone service) / 휴대폰 서비스를 가입한 고객만 해당됨.
InternetService : 인터넷 서비스 제공자 (DSL, Fiber optic, No)
OnlineSecurity : 온라인 보안 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
OnlineBackup : 온라인 백업 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
DeviceProtection 기기 보호 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
TechSupport : 기술 서포트 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
StreamingTV : TV 스트리밍 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
StreamingMovies : 영화 스트리밍 서비스를 가입 했는지의 여부 (Yes, No, No internet service) / 인터넷 서비스를 가입한 고객만 해당됨.
Contract : 계약 유형 (Month-to-month, One year, Two year)
PaperlessBilling : 전자 고지서 여부
PaymentMethod : 요금 지불 방법 (Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic))
MonthlyCharges : 매달 고객에게 청구되는 금액
TotalCharges : 고객에게 청구된 총 금액
Churn : 지난 한 달 내에 떠난 고객인지의 여부
3. 데이터셋 로딩
1. 데이터를 다루기 위한 라이브러리 import
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. 데이터셋을 로드한다.
df = pd.read_csv("/content/drive/MyDrive/dataset/통신사고객이탈.csv", index_col="customerID")
df.shape(7043, 20)위의 파일은 20개의 특성이 있고 데이터는 7043개가 있는 것을 확인 할 수 있다.
위의 파일을 구글 드라이브에 통신사고객이탈.csv 파일로 이름을 변경하여 업로드 해 두었다.
index_col을 customerID로 선언했다. 이것을 선언하지 않아도 되는데 이때는 index가 0부터 순서대로 매겨진다.
3. 데이터셋의 데이터 처음 5개를 출력해 본다.
df.head()

df.head() 로 확인을 하면 디폴트로 처음 5개의 데이터를 보여 준다. 만약 3개만 보고 싶다면 df.head(3) 과 같이 매개변수를 전달하면 된다.
우리는 tenure,MonthlyCharges,TotalCharges을 가지고 고객 이탈여부를 훈련해 보도록 하겠다.
실제로 데이터를 분석하다 보면 이 외에도 다양한 특징들을 이용해서 훈련해야 한다는 것을 알 수 있다.
4. 데이터 추출
df_data = df[['tenure','MonthlyCharges','TotalCharges','Churn']]5. 데이터 집합의 특징들의 자료형을 확인한다.
df_data.info()
여기서 아까 head() 로 보았을 때는 TotalCharges 가 숫자 타입이었는데 object 형인 것을 알 수 있다.
이것을 float 타입으로 형변환 해 준다. 우리는 MonthlyCarges,TotalCharges를 가지고 Churn 의 값을 예측할 예정이다.
6. 필요 특성의 형변환
df_data["TotalCharges"] = df_data["TotalCharges"].str.strip().replace("", np.nan).astype(float)숫자형태로 된 문자열을 숫자형으로 바꿔주는 명령어이다.
str.strip()로 양쪽 스페이스를 제거하고 만약 "" 과 같이 공백문자라면 np.nan 값으로 변경한 다음 float 형으로 변경해 준다.
다시 한번 특성의 자료형을 살펴 본다.
df_data.info()
float 형으로 바뀐것을 알 수 있다. 그런데 Non-Null 값이 7032로 바뀌었다.
결측치가 발생한 것이다.
7. 결측치의 갯수 확인
df_data.isnull().sum()11개의 결측치가 발생했다. 여기서 결측치가 있는 데이터를 가지고 훈련을 할 수가 없다.
결측치 값을 중간값,평균값으로 바꾸거나 아니면 삭제처리 해야 한다.

여기서 결측치가 11개 이므로 전체갯수 7043 이라면 미미한 숫자이다. 따라서 삭제하기로 하자.
8. 결측치 삭제
df_data = df_data.dropna()dropna() 메서드는 DataFrame에서 결측값이 포함된 데이터를 제거하는 메서드이다.
다시 확인해 보자.
df_data.isnull().sum()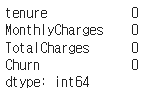
결측치가 사라진 것을 확인 할 수 있다.
9. 데이터 로딩 요약
데이터를 로딩하여 실제로는 이 보다 더 복잡한 과정을 거쳐 특성들을 분석하고 어떤 특성을 어떻게 전처리 해야 하는지 등은 데이터분석(EDA) 과정을 더 자세히 살펴 보아야 한다.
여기서는 최소한의 기본 과정으로 훈련 데이터를 만드는데 집중했다.
4. 테스트셋과 훈련셋 분할
- 데이터 분리하여 모양 출력
X=df_data[['tenure','MonthlyCharges','TotalCharges']]
y=df_data['Churn']
#훈련 데이터와 테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
#데이터 모양을 출력해 보자.
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
훈련데이터는 5274개 테스트데이터는 1758개 인것을 알 수 있다.
5. 학습
- 최근접 이웃 모델을 선택하여 학습
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)최근접 이웃 모델을 사용하는 방법은 간단하다. sklearn의 최근접이웃분류 모델을 import 하여
라이브러리를 이용하여 모델을 생성후 훈련(fit) 하면 결과가 나온다.
여기서는 3개의 특징과 1개의 YES,NO로 훈련했다.
점수를 확인해 보자.
6. 테스트 점수 확인
model.score(X_train, y_train)
model.score(X_test, y_test)
75점 정도 나왔다.
하지만 Chrun 데이터의 YES,NO의 갯수를 살펴 보면 다음과 같다.
df_data["Churn"].value_counts()
즉 73퍼센트가 No 이다. 따라서 모든 데이터를 No 라고만 출력해도 73점 정도는 나오는 것이다.
또한 훈련 점수와 테스트 점수가 많이 차이가 나므로 이것은 과대 적합이다. 과대적합을 줄이기 위해서는 최근접 이웃 모델에서는 k값을 조정해서 훈련할 수 있다.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=7)
model.fit(X_train, y_train)model.score(X_train, y_train)
model.score(X_test, y_test)
k 값을 7로 바꾸었더니 훈련 점수는 낮아지고 테스트 점수는 높아졌다. 이렇게 사람이 직접 조절 하는 파라미터를 하이퍼파라미터라고 한다.
우리는 이런 하이퍼파라미터를 조절하여 훈련하여 좀 더 좋은 점수가 나오는 모델을 생성하는 것이 머신러닝을 배우는 목적이다.
8. 맺음말
간단하게 실무에서 사용되는 데이터를 살펴 보았고~
이 데이터를 훈련하기 위해서 데이터를 처리하는 방법을 맛보기 정도로만 보았다.
최근접 이웃 모델에서는 하이퍼파라미터를 조절하여 테스트 점수가 78점 정도 나오는 모델을 만들어 볼 수가 있었는데~
앞으로 배우는 모델들을 통해 좀 더 의미있는 점수들을 만들어 보는 과정을 살펴 보도록 한다.
'강의자료 > 머신러닝' 카테고리의 다른 글
| 2.1 데이터 다루기 - 데이터 전처리 필요성 (8) | 2024.05.02 |
|---|---|
| 2.1 데이터 다루기 - 산점도 그려 보기(캐글 데이터셋 남자와 여자 분류) (3) | 2024.04.25 |
| 1.6 머신러닝 과정 (0) | 2024.04.11 |
| 1.5 머신러닝의 모델 구분 (0) | 2024.04.04 |
| 1.4 머신러닝에서 사용되는 용어 (10) | 2024.03.28 |