1. 주성분 분석(principal component analysis)란?
주성분 분석(PCA)은 고차원의 데이터를 저차원의 데이터로 환원시키는 기법을 말합니다.
이 때 서로 연관 가능성이 있는 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간(주성분)의 표본으로 변환하기 위해 직교 변환을 사용합니다.
이렇게 설명 했을 때 이해하기가 살짝 어려운데요~
주성분 분석이 어떤 경우에 사용되는지 먼저 살펴 보면 이해하기가 쉽습니다.
인공지능에서는 데이터의 차원이 엄청 많은데요~ 그러다 보니 계산 속도도 느려지고 저장할 수 있는 공간도 어마어마 해 집니다.
가령 3차원의 데이터를 살펴 보면 4 * 4 * 4 형태의 데이터가 있다면 저장할 수 있는 공간은 64개의 메모리 공간이 필요합니다.
이 데이터를 손실 없이 4 * 4 형태의 차원으로 축소한다면 메모리 공간은 16개로 확 줄어 들게 되겠네요~
이 처럼 고차원의 데이터를 데이터의 손실 없이 저차원의 데이터로 압축 하는 기법을 주성분 분석(PCA) 라고 합니다.
그렇다면 주성분 분석은 어떻게 이루어 지는 것일까요?
주성분 분석은 데이터에 있는 분산이 큰 방향을 찾는 것으로 이해하면 됩니다.
분산은 데이터가 널리 퍼져 있는 정도를 말하는데 이러한 분산이 큰 방향이란 데이터를 잘 표현 하는 어떤 벡터라고 생각 할 수 있습니다.
다음과 같은 2차원 데이터를 1차원 데이터로 만드는 방법에 대해 살펴 보시죠~
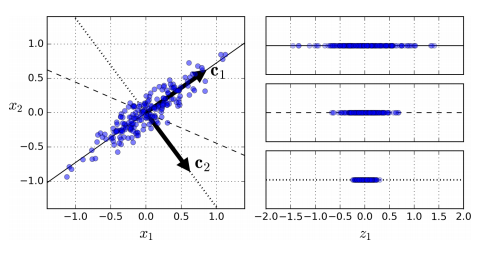
왼쪽의 x1의 2차원 데이터를 z1 의 1차원 데이터로 만들려고 합니다.
이때 데이터 손실을 최소로 하고 싶다면 C1의 벡터에 데이터를 투영을 하게 되면 z1의 맨 위의 1차원 이미지가 됩니다.
C2 를 선택 하는 경우 맨 아래의 이미지 처럼 데이터가 모이기 때문에 분산이 적어지면서 여러가지 특성이 사라지게 됩니다.
만약 고차원의 데이터를 2차원의 데이터로 압축하려고 한다면
한개의 축으로 사상 시켰을 때 그 분산이 가장 커지는 축을 첫번째 주성분으로 선택하고
두번째로 커지는 축을 두번째 주성분으로 놓이도록 새로운 좌표계로 데이터를 선형 변환 하는 것이 주성분입니다.
다음은 혼자공부하는 머신러닝 책에 나온 주성분 분석에 대한 실습 예를 살펴 보도록 하겠습니다.
2. PCA 클래스
과일 사진 데이터를 사이킷런의 PCA클래스로 주성분 분석을 수행해 봅니다.
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)넘파이 배열에 과일 사진을 적재했습니다.
PCA클래스의 객체를 만들때 n_components 매개변수에 주성분의 개수를 지정해야 합니다.
k-평균과 마찬가지로 비지도 학습이기 때문에 fit() 메서드에 타깃값을 제공하지 않습니다.
from sklearn.decomposition import PCA
pca = PCA(n_components=50)
pca.fit(fruits_2d)PCA 가 찾은 주성분은 components_ 속성에 저장되어 있습니다.
이 배열의 크기를 확인해 보겠습니다.
print(pca.components_.shape)
n_components 를 50으로 지정했기 때문에 첫번째 차원이 50입니다. 즉 50개의 주성분을 찾은 것입니다.
두번째 차원은 항상 원본 데이터의 특성 개수와 같은 10000 입니다.
원본 데이터와 차원이 같으므로 주성분을 100 * 100 크기의 이미지 처럼 출력해 볼 수 있습니다.
draw_fruits() 함수를 사용해서 주성분을 그려 봅니다.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) # n은 샘플 개수입니다
# 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n: # n 개까지만 그립니다.
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_fruits(pca.components_.reshape(-1, 100, 100))
이 주성분은 원본 데이터에서 가장 분산이 큰 방향을 순서대로 나타낸 것입니다. 한편으로는 데이터셋에 있는 어떤 특징을 잡아낸 것처럼 생각할 수도 있습니다.
주성분을 찾았으므로 원본데이터를 주성분에 투영하여 특성의 개수를 10000개에서 50개로 줄일 수 있습니다.
이는 마치 원본 데이터를 각 주성분으로 분해하는 것으로 생각할 수 있습니다.
PCA의 transform() 메서드를 사용해 원본 데이터의 차원을 50으로 줄여 봅니다.
print(fruits_2d.shape)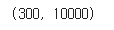
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)
10000개의 특성을 가진 이미지 데이터가 50개의 특성을 가진 배열로 변환 되었습니다.
그렇다면 이렇게 데이터 차원이 줄어 들었는데 원상 복구도 가능할까요?
3. 원본 데이터 재구성
10000개의 특성을 50개로 줄였으므로 어느정도 손실이 발생 할 수 밖에 없습니다.
하지만 최대한 분산이 큰 방향으로 데이터를 투영했기 때문에 원본 데이터를 상당 부분 재 구성 할 수 있습니다.
PCA 클래스는 이를 위해 inverse_transform()메서드를 제공합니다.
복원을 해 보겠습니다.
fruits_inverse = pca.inverse_transform(fruits_pca)
print(fruits_inverse.shape)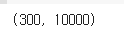
fruits_reconstruct = fruits_inverse.reshape(-1, 100, 100)for start in [0, 100, 200]:
draw_fruits(fruits_reconstruct[start:start+100])
print("\n")


약간 흐리고 번진 부분은 있지만 50개의 특성만으로 충분히 이미지를 잘 보존 된 것을 확인 할 수 있었습니다.
만약 주성분을 최대로 사용했다면 완벽하게 원본 데이터를 재구성 할 수 있을 것입니다.
참고)
https://butter-shower.tistory.com/210
한빛미디어 - 혼자 공부하는 머신러닝
'강의자료 > 인공지능수학' 카테고리의 다른 글
| [인공지능수학] 등차수열의 합 실습하기 (19) | 2023.01.06 |
|---|---|
| [인공지능수학] 함수의 개념 실습하기 (7) | 2022.12.16 |
| [인공지능수학]MNIST (7) | 2022.10.31 |
| [인공지능수학] 경사하강법으로 학습하는 방법 알아 보기 (6) | 2022.10.06 |
| [인공지능수학] 표준편차 (5) | 2022.08.10 |