도미와 빙어를 분류하는 머신러닝을 만들기 위한 데이터 준비를 알아 보겠습니다.
1. 데이터 준비
먼저 도미와 빙어 데이터가 포함된 데이터를 구하러 가 보시죠.
캐글에는 많은 데이터가 제공되고 있습니다.
캐글에서 제공하는 물고기 데이터를 다운받아 보겠습니다.
https://www.kaggle.com/datasets/aungpyaeap/fish-market
Fish market
Database of common fish species for fish market
www.kaggle.com
해당 사이트에 들어가서 Download 버튼을 클릭하여 데이터를 다운 받을 수 있습니다.
다운을 받아 압축을 해제 하면 Fish.csv 파일이 있습니다.
이 파일을 구글 드라이버에 로딩 후 작업을 진행 하겠습니다.
자신의 구글 드라이버에 Fish.csv 파일을 업로드 합니다.

저는 Colab Notebooks 디렉토리에 deeplearning 폴더를 만들고 Fish.csv 파일을 업로드 했습니다.
코랩에서 드라이브에 있는 파일을 사용하기 위해서는 다음과 같은 작업을 수행해야 합니다.
코랩을 생성하는 시점에 가상의 서버를 생성하기 때문에 내 드라이브에 있는 파일을 가상의 서버에 연결을 해 주어야 합니다.
import os, sys
from google.colab import drive
drive.mount('/content/drive')위와 같이 입력 후 실행을 하면 다음과 같은 메시지가 출력 됩니다. 여기서 Googl Dreve 연결을 해 주시면 됩니다.

연결 후 폴더를 새로 고침하면 다음과 같이 drive 가 생성 되어 있는 것을 확인 할 수 있습니다.

좀 전에 만든 폴더는 drive -> MyDrive -> Colab Notebooks -> deeplearning 폴더로 접근이 가능합니다.
업로드 된 파일을 판다스를 이용해 로딩 해 보시죠.
import pandas as pd
df = pd.read_csv('./drive/MyDrive/Colab Notebooks/deeplearning/Fish.csv')
df.head()
파일의 특성을 살펴 보니 Species,Weight,Length1,Length2,Length3,Height,Width 를 가지고 있는 파일이네요.
이 특성의 내용을 살펴 보겠습니다.
캐글에서 제공하는 내용을 살펴보면 다음과 같은 것을 알 수 있습니다.

Species : 물고기 종류
Weigth : 물고기 무게(g)
Length1 : 세로길이(cm)
Length2 : 대각선길이(cm)
Length3 : 십자길이(cm)
Height : 높이(cm)
Width : 대각선 너비(cm)
우리는 여기서 Length2(대각선길이),Weight(무게) 를 가지고 훈련해서 물고기의 종류를 찾아내는 머신러닝을 만들어 보겠습니다.
먼저 이 데이터의 물고기 종류가 몇가지 인지 파악해 보도록 하겠습니다.
df.groupby('Species').count()종류를 구분으로 데이터의 갯수를 살펴 보면 다음과 같습니다.

7가지 물고기 종류가 있군요.
여기서 도미(Bream) 데이터는 35개,빙어(Smelt) 는 14개의 데이터가 있는 것을 확인 할 수 있습니다.
도미데이터와 빙어 데이터의 산점도를 확인해 보죠.
bream_length = df[(df['Species']=='Bream')]['Length2'].values.tolist()
bream_weight = df[(df['Species']=='Bream')]['Weight'].values.tolist()
smelt_length = df[(df['Species']=='Smelt')]['Length2'].values.tolist()
smelt_weight = df[(df['Species']=='Smelt')]['Weight'].values.tolist()
import matplotlib.pyplot as plt
plt.scatter(bream_length,bream_weight)
plt.scatter(smelt_length,smelt_weight)
plt.xlabel('length') #x축 라벨
plt.ylabel('weight') #y축 라벨
plt.show() # 산점도 확인
도미 데이터와 빙어 데이터만 추출합니다.
breamSmelt = df[(df['Species']=='Bream')|(df['Species']=='Smelt')]
print(breamSmelt)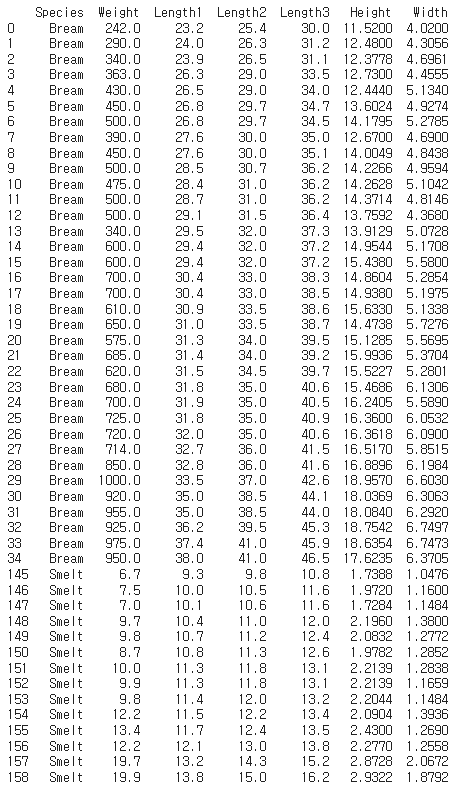
Spices 가 Bream 은 0, Smelt 은 1으로 데이터를 변경하겠습니다.
breamSmelt['Species'] = breamSmelt['Species'].apply(lambda x : 0 if x =='Bream' else 1)
print(breamSmelt)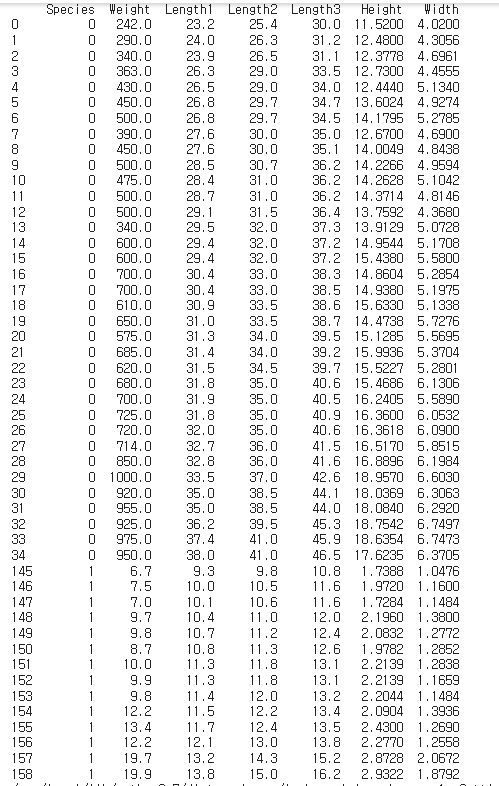
Spices 를 target 으로 훈련데이터는 Length2,Weight 를 쌍으로 하는 훈련데이터를 만들겠습니다.
target = list(breamSmelt['Species'].values)
print(target)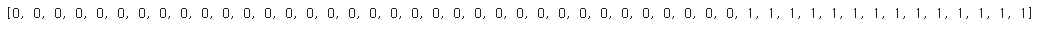
data = breamSmelt[['Length2','Weight']].values.tolist()
print(data)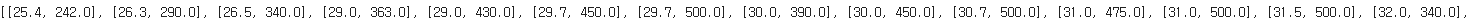
이제 훈련할 데이터 추출에 성공했습니다.
다음에는 이 데이터를 가지고 머신러닝을 만들어 보도록 하겠습니다.
[참고]
한빛미디어 : 혼자 공부하는 머신러닝
'강의자료 > 머신러닝' 카테고리의 다른 글
| 1.3 머신러닝 시스템의 종류 (7) | 2024.03.21 |
|---|---|
| 1.2 머신러닝을 사용하는 이유 (0) | 2024.03.14 |
| 1.1 인공지능이란 (0) | 2024.03.07 |
| 머신러닝 목차 (0) | 2024.02.29 |
| 머신러닝] 교차검증으로 평가하기 (18) | 2023.12.13 |