표준편차를 알기 전에 평균,기댓값,분산 의 의미를 먼저 이해 합니다.
1. 기댓값
기댓값(expected value)는 '나올 것이라고 예상하는 값' 입니다.
x가 확률변수이고 P(x)인 사건이 벌어질 때, 예상할 수 있는 결과값이 기댓값입니다.
이것은 어떤 확률적 사건에 대한 평균의 의미로 생각할 수 있습니다.
이 것을 공식으로 다음과 같이 표현 합니다.
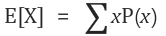
예를 들어 1~6까지 있는 주사위를 던졌을 때 나오는 기댓값은 다음과 같습니다.
1이 나올 확률 1/6
2가 나올 확률 1/6
3이 나올 확률 1/6
4가 나올 확률 1/6
5가 나올 확률 1/6
6이 나올 확률 1/6
따라서 E[x]=1*1/6 + 2 * 1/6 + 3*1/6 + 4*1/6 + 5*1/6 + 6 *1/6 = 3.5 가 됩니다.
2. 평균
다음과 같이 온라인 쇼핑몰의 매출액이 있다고 가정합니다.
| 고객명 | 1월 | 2월 | 3월 | 합계 |
| 홍길동 | 30000 | 30000 | 30000 | 90000 |
| 이순신 | 1500 | 45000 | 13500 | 60000 |
| 강감찬 | 2000 | 0 | 7000 | 9000 |
이렇게 3개월의 매출을 근거로 이후 한달동안 매출이 어느정도 나올지 기댓값을 구해보는 것이 평균입니다.
이 기댓값(평균)을 구해 보면 홍길동-30000,이순신-20000,강감찬-3000 이 됩니다.
3. 편차
위의 예에서 홍길동은 꾸준히 30000원씩의 매출이 발생했지만, 이순신/강감찬은 각각 서로 다른 패턴을 보여주게 됩니다.
즉 이번달에 이순신이 20000,강감찬이 3000원이 된다는 보장이 없습니다.
그래서 평균값과 데이터의 차이(편차)를 살펴 보면 다음과 같습니다.
| 고객명 | 1월 | 2월 | 3월 | 합계 |
| 홍길동 | 0 | 0 | 0 | 0 |
| 이순신 | -18500 | 25000 | -75000 | 0 |
| 강감찬 | -1000 | -3000 | 4000 | 0 |
위와 같이 편차의 관점에서 매출액이 고객별로 흩어져 있는 것을 알 수 있습니다.
이 편차들의 합을 구해 보면 모두 0이 되는데 이러한 편차를 구해서 합치는 것만으로는 매출의 흩어진 정도를 알 수 없습니다.
4. 분산
위에서 본 편차의 데이터는 (+)와 (-) 모두 있기 때문에 합치면 0 이 되는 것을 확인 할 수 있습니다.
따라서 데이터의 흩어진 정도를 얻어내려면 (+)와 (-) 부호를 없애 줘야 하는데 편차를 제곱한 다음 합계를 구하고 이것을 다시 평균값으로 만들면 분산이 됩니다.
| 고객명 | 1월 | 2월 | 3월 | 합계 |
| 홍길동 | 0 | 0 | 0 | 0 |
| 이순신 | 342,250,000 | 625,000,000 | 5,625,000,000 | 6,592,250,000 |
| 강감찬 | 1,000,000 | 9,000,000 | 16,000,000 | 26,000,000 |
이렇게 하면 홍길동의 분산은 0 이순신의 분산은 2,197,416,666 강감찬의 분산은 8,666,666 이 된다.
분산을 구하는 공식은 다음과 같습니다.

5. 표준편차
위와 같이 분산을 구했을 때 본래 단위 의미를 찾기 위해 분산에 제곱근을 사용하게 되는데 이것이 표준편차 입니다.
따라서 표준편차는 홍길동 0, 이순신 46876, 강감찬 2943 이 됩니다.
이렇게 분산과 표준편차를 이용하면 데이터의 경향을 표현 할 수가 있습니다.
표준편차를 구하는 공식은 다음과 같습니다.

| 인공지능에서 활용 |
평균과 분산,그리고 표준편차는 과거의 데이터로부터 어떤 특징이나 경향을 밝혀 낼 수 있는 가장 기본적인 방법입니다.
인공지능 모델을 만들기 전에 데이터의 특징을 파악할 때 사용합니다.
[참고]
인공지능을 위한 수학
'강의자료 > 인공지능수학' 카테고리의 다른 글
| [인공지능수학]MNIST (7) | 2022.10.31 |
|---|---|
| [인공지능수학] 경사하강법으로 학습하는 방법 알아 보기 (6) | 2022.10.06 |
| [인공지능수학] 상관계수 (10) | 2022.07.11 |
| [인공지능수학] 확률 (7) | 2022.04.04 |
| [인공지능 수학] 행렬 (11) | 2022.03.25 |